Goal
The goal of rperseus is to furnish classicists, textual critics, and R enthusiasts with texts from the Classical World. While the English translations of most texts are available through gutenbergr, rperseusreturns these works in their original language–Greek, Latin, and Hebrew.
Description
rperseus provides access to classical texts within the Perseus Digital Library’s CapiTainS environment. A wealth of Greek, Latin, and Hebrew texts are available, from Homer to Cicero to Boetheius. The Perseus Digital Library includes English translations in some cases. The base API url is http://cts.perseids.org/api/cts.
Installation
rperseus is not on CRAN, but can be installed via:
devtools::install_github("ropensci/rperseus")Usage
See the vignette to get started.
To obtain a particular text, you must first know its full Uniform Resource Name (URN). URNs can be perused in the perseus_catalog, a data frame lazily loaded into the package. For example, say I want a copy of Virgil’s Aeneid:
library(dplyr)
library(purrr)
library(rperseus)
aeneid_latin <- perseus_catalog %>%
filter(group_name == "Virgil",
label == "Aeneid",
language == "lat") %>%
pull(urn) %>%
get_perseus_text()You can also request an English translation for some texts:
aeneid_english <- perseus_catalog %>%
filter(group_name == "Virgil",
label == "Aeneid",
language == "eng") %>%
pull(urn) %>%
get_perseus_text()Refer to the language variable in perseus_catalog for translation availability.
Excerpts
You can also specify excerpts:
qoheleth <- get_perseus_text(urn = "urn:cts:ancJewLit:hebBible.ecclesiastes.leningrad-pntd", excerpt = "1.1-1.3")
qoheleth$text
#> [1] "דִּבְרֵי֙ קֹהֶ֣לֶת בֶּן־ דָּוִ֔ד מֶ֖לֶךְ בִּירוּשָׁלִָֽם : הֲבֵ֤ל הֲבָלִים֙ אָמַ֣ר קֹהֶ֔לֶת הֲבֵ֥ל הֲבָלִ֖ים הַכֹּ֥ל הָֽבֶל : מַה־ יִּתְר֖וֹן לָֽאָדָ֑ם בְּכָל־ עֲמָל֔וֹ שֶֽׁיַּעֲמֹ֖ל תַּ֥חַת הַשָּֽׁמֶשׁ :"Parsing Excerpts
You can parse any Greek excerpt, returning a data frame with each word’s part of speech, gender, case, mood, voice, tense, person, number, and degree.
parse_excerpt("urn:cts:greekLit:tlg0031.tlg002.perseus-grc2", "5.1-5.2") %>%
head(7) %>%
knitr::kable()| word | form | verse | part_of_speech | person | number | tense | mood | voice | gender | case | degree |
|---|---|---|---|---|---|---|---|---|---|---|---|
| καί | Καὶ | 5.1 | conjunction | NA | NA | NA | NA | NA | NA | NA | NA |
| ἔρχομαι | ἦλθον | 5.1 | verb | third | plural | aorist | indicative | active | NA | NA | NA |
| εἰς | εἰς | 5.1 | preposition | NA | NA | NA | NA | NA | NA | NA | NA |
| ὁ | τὸ | 5.1 | article | NA | singular | NA | NA | NA | neuter | accusative | NA |
| πέραν | πέραν | 5.1 | adverb | NA | NA | NA | NA | NA | NA | NA | NA |
| ὁ | τῆς | 5.1 | article | NA | singular | NA | NA | NA | feminine | genative | NA |
| θάλασσα | θαλάσσης | 5.1 | noun | NA | singular | NA | NA | NA | feminine | genative | NA |
tidyverse and tidytext
rperseus plays well with the tidyverse and tidytext. Here I obtain all of Plato’s works that have English translations available:
library(purrr)
plato <- perseus_catalog %>%
filter(group_name == "Plato",
language == "eng") %>%
pull(urn) %>%
map_df(get_perseus_text)And here’s how to retrieve the Greek text from Sophocles’ underrated Philoctetes before unleashing the tidytext toolkit:
library(tidytext)
philoctetes <- perseus_catalog %>%
filter(group_name == "Sophocles",
label == "Philoctetes",
language == "grc") %>%
pull(urn) %>%
get_perseus_text()
philoctetes %>%
unnest_tokens(word, text) %>%
count(word, sort = TRUE) %>%
anti_join(greek_stop_words)
#> Joining, by = "word"
#> # A tibble: 3,514 x 2
#> word n
#> <chr> <int>
#> 1 νεοπτόλεμος 164
#> 2 φιλοκτήτης 141
#> 3 ὦ 119
#> 4 μʼ 74
#> 5 ὀδυσσεύς 56
#> 6 τέκνον 47
#> 7 τʼ 43
#> 8 χορός 41
#> 9 γʼ 40
#> 10 νῦν 39
#> # ... with 3,504 more rowsRendering Parallels
You can render small parallels with perseus_parallel:
tibble(label = c("Colossians", "1 Thessalonians", "Romans"),
excerpt = c("1.4", "1.3", "8.35-8.39")) %>%
left_join(perseus_catalog) %>%
filter(language == "grc") %>%
select(urn, excerpt) %>%
pmap_df(get_perseus_text) %>%
perseus_parallel(words_per_row = 4)
#> Joining, by = "label"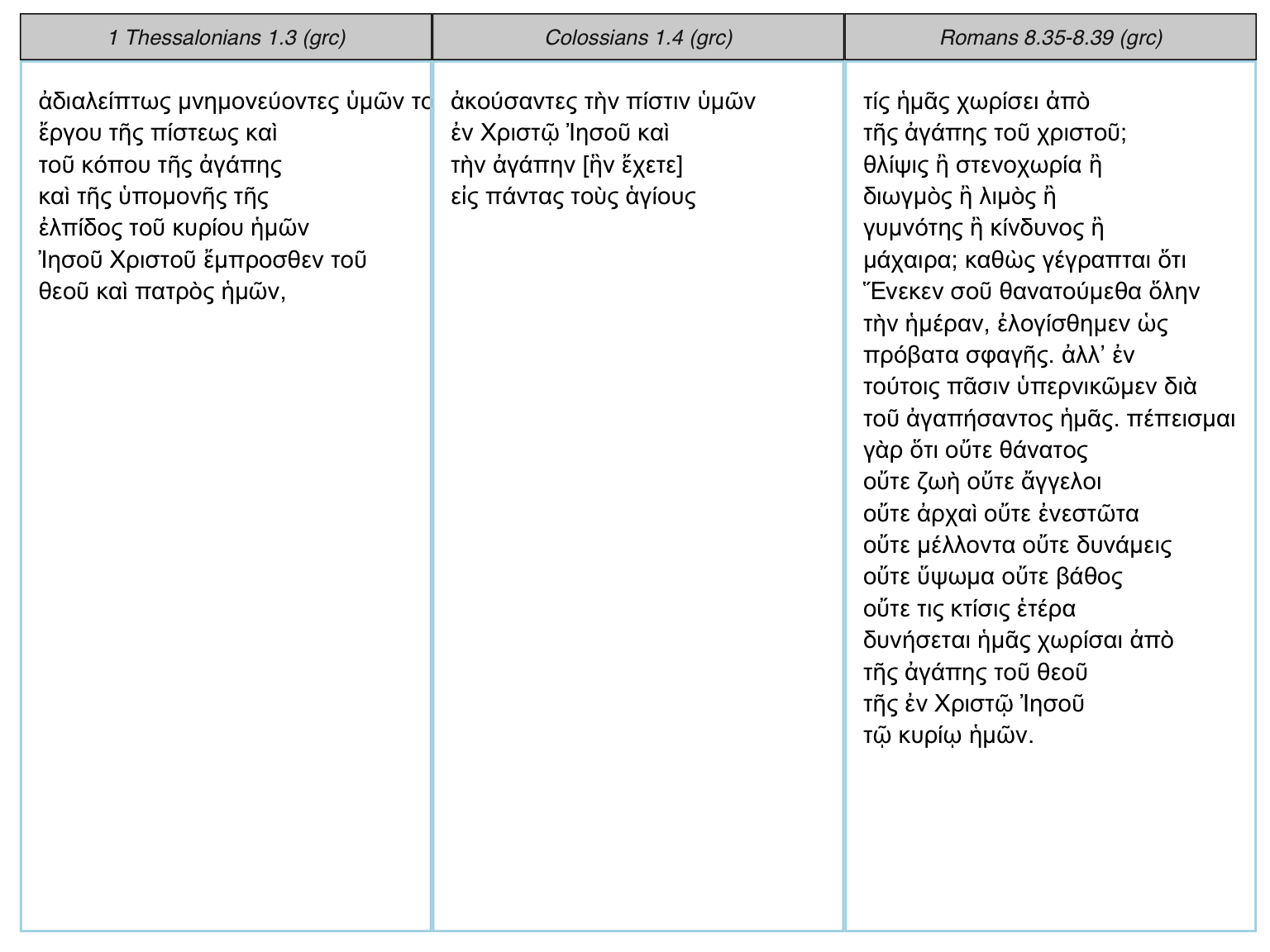
Meta
- Report bugs or issues here.
- If you’d like to contribute to the development of
rperseus, first get acquainted with the Perseus Digital Library, fork the repo, and send a pull request. - This project is released with a Contributor Code of Conduct. By participating in this project, you agree to abide by its terms.


